4. Create a Business Unit Data pipeline
This tutorial is a part of the series - Guided set up.
Business Units - API Documentation
Pipeline Requirements
Pipeline Schedule - Run it once a day at 6 A.M. Eastern Time.
Data fetch strategy: We want to fetch all the Business Unit records everyday and replace the existing set of Business Unit records. This is FULL REFRESH dedupe strategy.
In data warehousing [Business Units] is qualified as a dimension. Business Units is a slowly changing data and the number of records are very less. This allows us to run the Business Unit on a FULL REFRESH dedupe strategy.
In FULL REFRESH - all the existing records are deleted and are overwritten with the new records.
Data Schema requirements: If ServiceTitan adds a new field to the APIs, automatically include that.
Data Storage
Azure Blob - In the Azure blob create a folder for Business Units. Within Business Units folder create a folder for every day's data run.
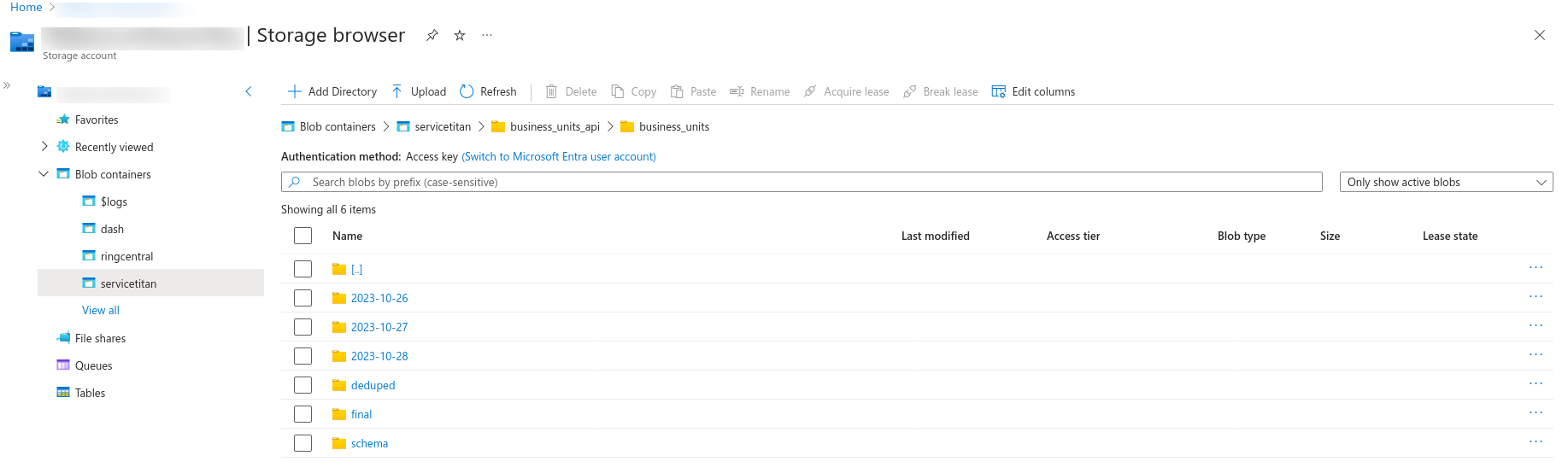
AzureSQL - Create a new table - "business_units" in "servicetitan" schema and write the data to it.
Pipeline set up
- Navigate to Integrations Tab in ELT Data and click on "Select Data" for ServiceTitan to ReportingDB integration.
- Click on the "+ Add New Dataset".
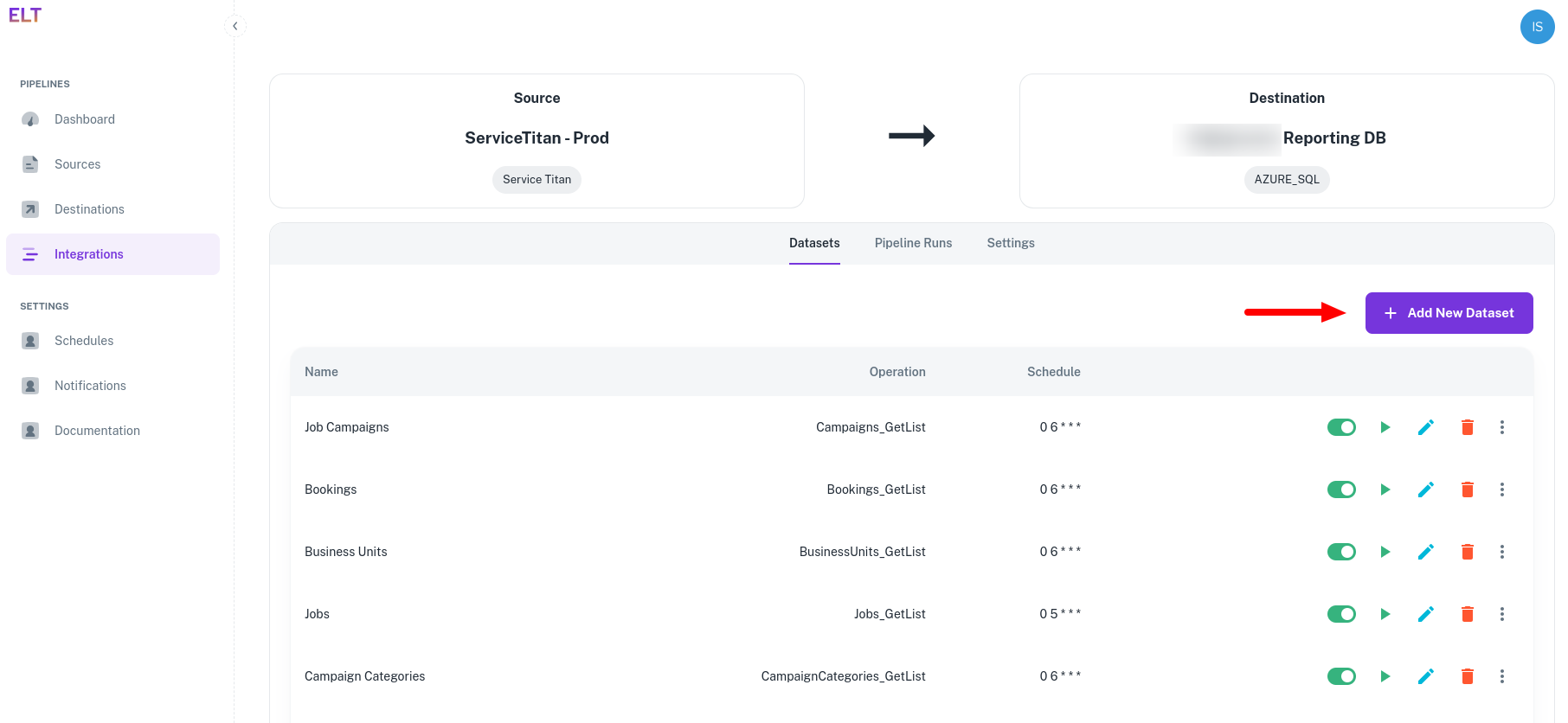
Setting up the data pipeline is a three step process.
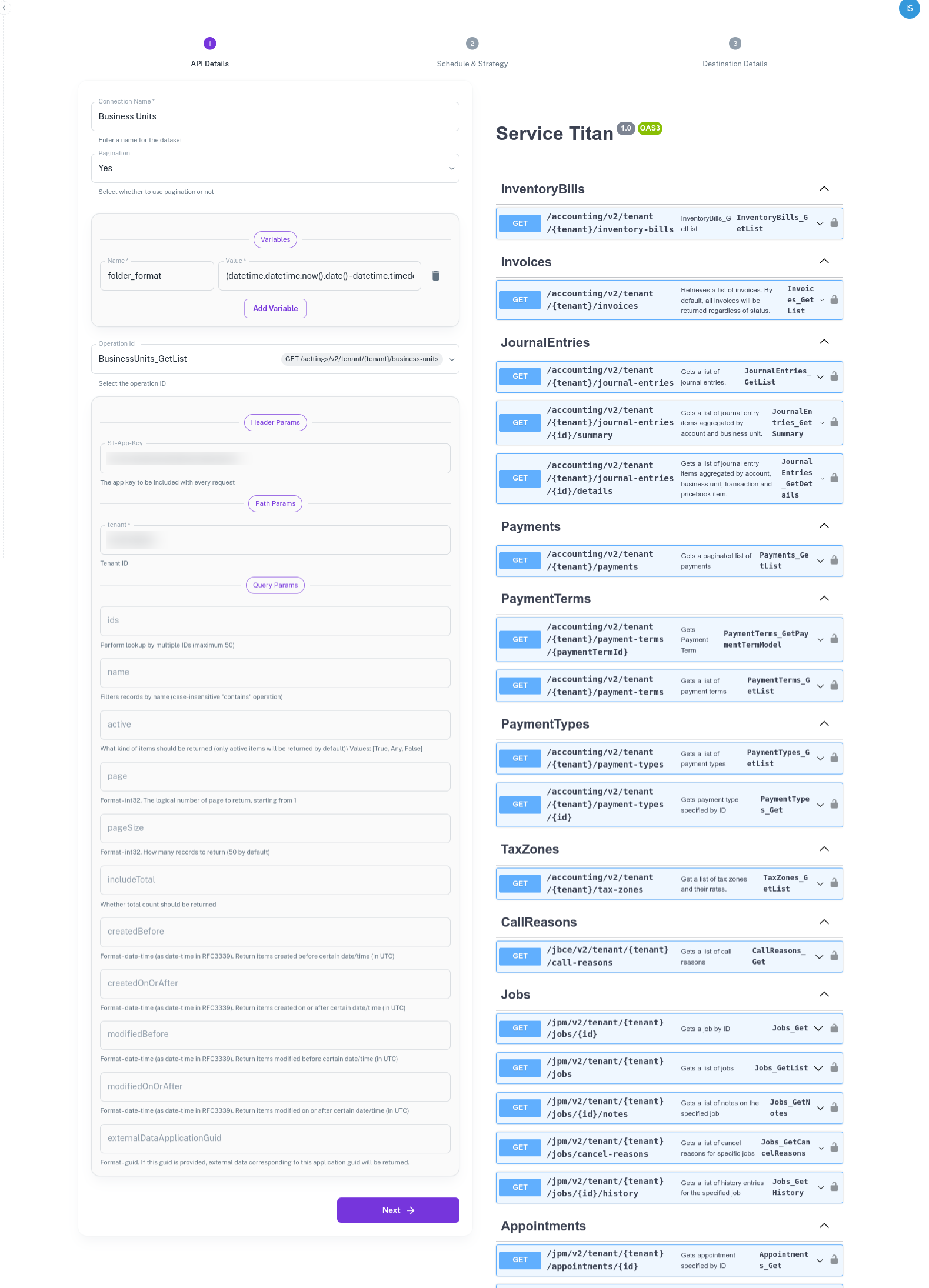
API Details - Specify the API from which you want to fetch the data.
Connection/Pipeline Name - Give your dataset a name
Pagination - Switch it On. ELT Data automatically paginates over the APIs. If the API supports pagination, switch it On.
OperationId - Select the API from which you want to fetch the data.
Variables - These are dynamic inputs to the APIs. For e.g - date parameters or dynamic strings. These variables are used for defining the folder format too. Create a variable - folder_format and provide the value -
(datetime.datetime.now().date() - datetime.timedelta(days=1)).strftime('%Y-%m-%d'). This will create a datewise folder in the blob. The variables are python datetime functions and can support wide variety of input/output formats.API Parameters - The API parameters are rendered based on the selected API. Populate the ST-App-Key and TenantID. You get these values on setting up API authentication. Leave the rest of the fields blank. In case of required/mandatory variables, you will be requested to provide those values too.
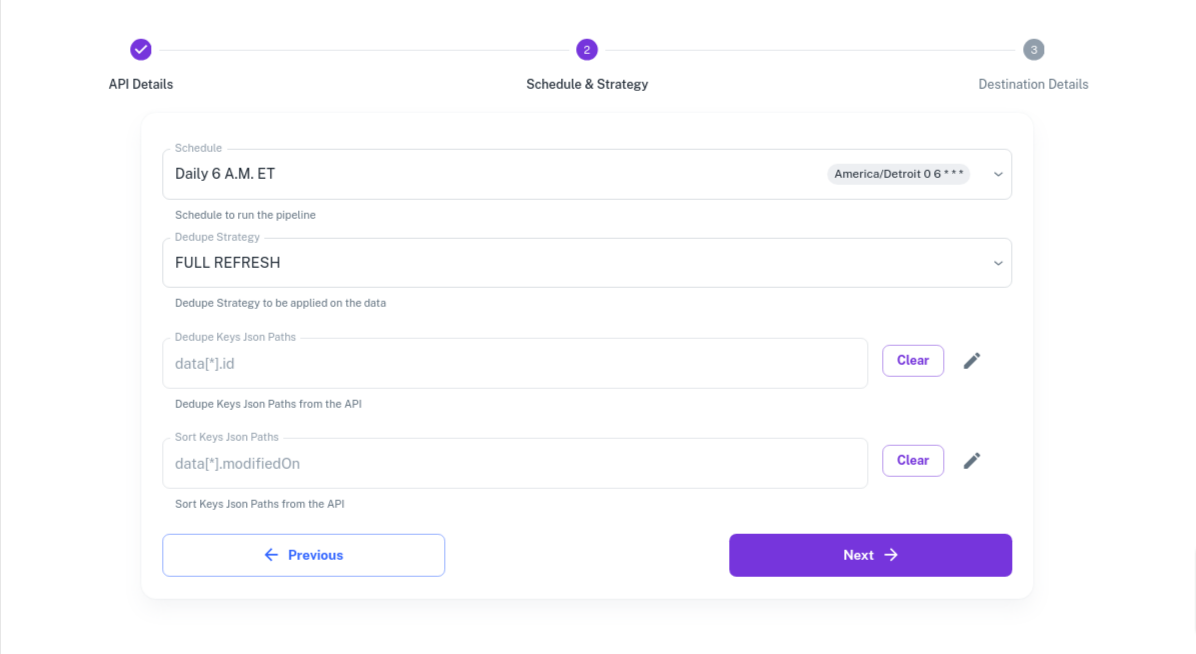
Schedule and Data fetch strategy - Schedule and how do you want to overwrite the data in your warehouse.
- Select the 6 A.M. ET schedulel rr create a new schedule in the Schedules Tab under "Settings".
- Dedupe Strategy - Set it to FULL Refresh
- Dedupe Keys Json Paths - Leave it blank or select one the ID fields. Dedupe and Sort Key documentation
- Sort Keys Json Paths - Leave it blank or select on of the fields. Dedupe and Sort Key documentation
Destination Details - Destination details
Under Destination Details we have to specify where to write the data in the AzureBlob and where do we want to write the final data in AzureSQL.
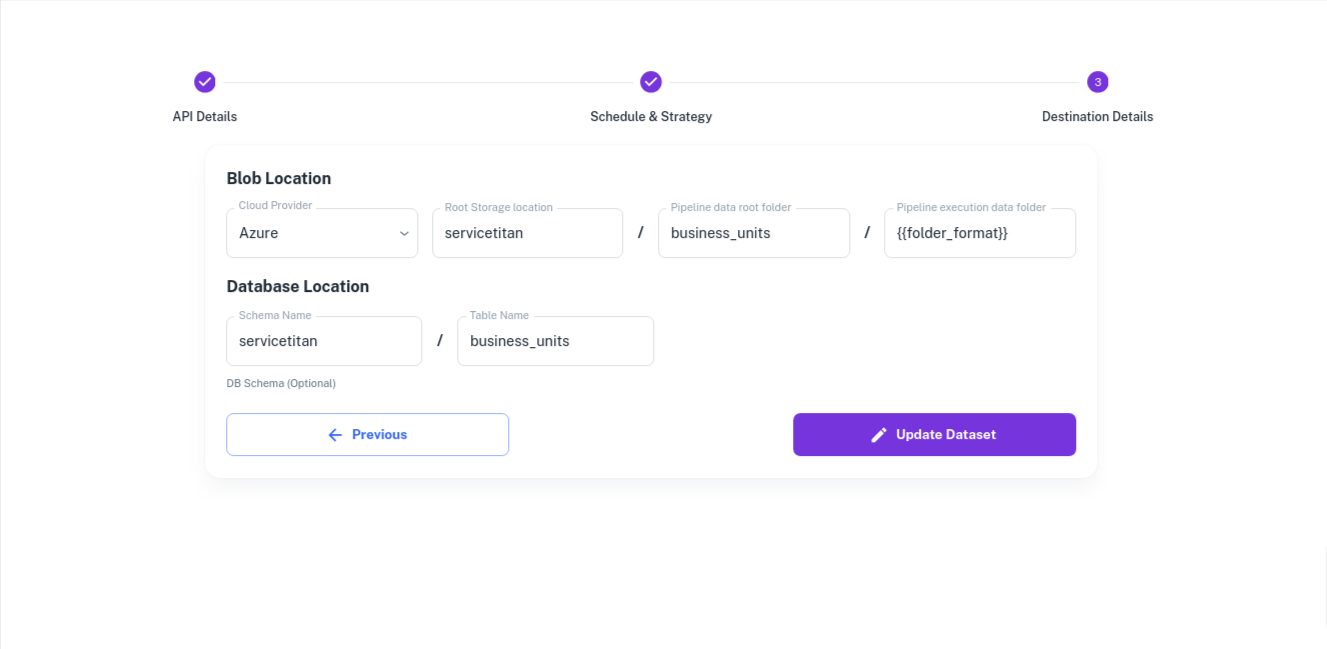
{{folder_format}}refers to the variable we created on the first page. For everyday's execution a new folder will be created using the variable{{folder_format}}and the data will be written to it.- The final deduped data ia available in - "final" folder.
- The schema changes are being tracked under the "schema" folder.
Sample output in Azure Blob.
Save the form and exit the page.
With the above steps the pipeline will run on schedule or you can navigate to the Integrations -> "Your Integration" -> Select Dataset and click on Run now to run your pipeline.
The pipeline execution status will be visible on the dashboard and the failure notifications will be sent to the emails specified in the "Notifications" tab under settings.
Pipeline Execution
The pipeline will execute in your environment. This can be audited by checking the Azure Container Instances logs.